

คำอธิบาย
K-Nearest Neighbors – Machine Learning ด้วย Python
In the vast realm of machine learning algorithms, few techniques stand as versatile and intuitive as the K-nearest neighbors (KNN) algorithm. If you’re seeking a powerful tool for pattern recognition, classification, and regression tasks, KNN offers a straightforward yet effective approach that leverages the power of proximity.

So, what exactly is the K-nearest neighbors algorithm? At its core, KNN is a supervised machine learning algorithm that excels at classification and regression tasks. The KNN algorithm works based on the idea that similar things are closer to each other.
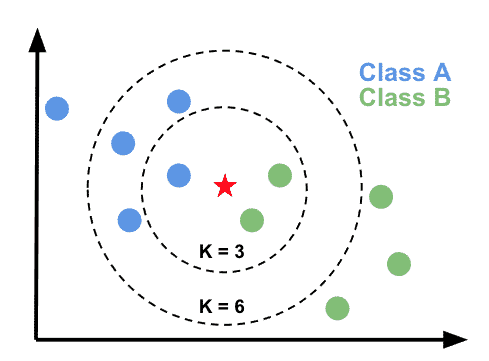
Imagine you have a dataset of different flowers, each described by their petal length and width. You also have labels indicating whether each flower is a rose or a daisy. Now, you encounter a new flower and want to determine its type. This is where KNN comes into play. Now, In this flower example, KNN looks at the flower’s nearest neighbors to decide its type. Let’s say we set K = 3, meaning we’ll consider the three closest neighbors to make our prediction. To determine the type of the new flower using KNN, here’s what we’ll do:
- Measure the distance: Calculate the distance between the new flower and all the flowers in the dataset. In our case, we can use the Euclidean distance, which is like measuring the straight-line distance between two points. The distance is computed based on the petal length and width.
- Find the K nearest neighbors: Identify the K flowers with the shortest distances to the new flower. These are the K nearest neighbors. For instance, if K = 3, we select the three flowers that are closest to our new flower.
- Majority voting: Among the K nearest neighbors, count how many are roses and how many are daisies. Whichever type has the majority becomes our prediction for the new flower. For example, if two neighbors are roses and one is a daisy, we predict that the new flower is a rose.



